At Juristat, we use big data analytics to help patent lawyers predict the future. As of the Summer of 2014, our dataset includes over 5.5 million U.S. patent applications, with some applications dating back to the early 1900s. Each patent application is made up of a series of interrelated documents stored in tsv or xml formats. Further, patent applications can be connected to other applications through parent-child relationships. Unlike most big data projects with large constantly streaming data feeds, the patent system moves at a glacial pace, with an average application receiving an new event once every few months. We’ve begun the transition from our existing MySQL database system to a NoSQL document store, and based on our needs we considered MongoDB and RethinkDB as potential solutions. Below are the findings of our benchmarking and testing
An Introduction to MongoDB and RethinkDB
Both MongoDB and RethinkDB are document stores. Though they are a significant departure from more traditional tabular database systems like MySQL and PostgreSQL, they are perfect for us at Juristat. Everything that happens around a patent application is an actual document, from the fee worksheets to the issue notification. In our current system, we have to split documents into different tables to effectively use them, but with a document store, everything can be organized into manageable nested documents, which are easy to import, update, and query. That is the driving factor for this investigation.
A Brief History of MongoDB and RethinkDB
Work began on MongoDB in 2007, and was released in 2009 as an open-source project. The first “production-ready” release was version 1.4, released in 2010. The current version (used in these tests) is 2.6.3. RethinkDB was announced in 2009, but the first released in 2012 as version 1.2. There have been frequent updates since then, and the current version (used in these tests) is 1.13.1.
First Impressions
I began the tests with RethinkDB. Many in the office were rooting for RethinkDB because of its excellent UI and simple sharding. The UI offers a lot of cool visualization and functionality which we heavily used to help manage the test server. From the UI, we could create secondary indexes, experiment with sharding, and run our prototype queries until the actual benchmarking began.
MongoDB, on the other hand, does not provide any UI other than a general administration page. In order to help make queries and organize data in a browsable manner when working with MongoDB, we did all of our testing in a program called Robomongo (similar in function to MySQL Workbench, though more lightweight).
Documentation
One of the most important things to look for in software like MongoDB and RethinkDB is solid documentation. Through the course of our testing, we found that RethinkDB’s documentation is easier to navigate, using tabs to switch between languages like Javascript and Python, a column of different functions in categories, and simple examples to the right.We feel MongoDB’s documentation is almost awkward, splitting topics into different sections that were not easy to navigate for those just looking for straight definitions. Thankfully, MongoDB’s documentation has a useful overview page for the aggregation function that lists all of the important details. However, MongoDB is superior when it comes to usage examples for its functions. For instance, RethinkDB provides only an example of map-reduce to count the number of items in a particular dataset, then dismissively tells the reader to just use the dedicated count function anyway (which is correct, but very unhelpful to those new to map-reduce). MongoDB has many more examples, including summations, averages of arbitrary fields, and how to pre-process data before mapping. The trend of good examples from MongoDB and lackluster examples from RethinkDB continues on to many other functions.
API
At first glance, the APIs for both systems are pretty similar. Though the language differs in places, both offer simple ways to filter for specific values (like looking for all documents related to a single patent examiner, or for all of the applications from April 2010), sort the stream of data coming from a collection of documents, and transform the data to use elsewhere. Both are compatible with Javascript, Python, and Ruby. MongoDB also offers official drivers for many other languages like Java and C#, while RethinkDB relies on community-supported drivers. For developers coming from SQL-based systems, RethinkDB features many of the same statements, such as table joins that can make the switch easier. However, for the purposes of this test, we did not find a good use case for these statements. Instead we used other functions like mapping and grouping to write our queries. One major difference between MongoDB and RethinkDB is the syntax. While RethinkDB uses chained functions, MongoDB uses nested objects in which keys are the names of functions and values are the arguments. Both work as intended, though we personally prefer MongoDB’s method, given that chaining functions can get visually messy with some complex queries.
Benchmarking
One of the most important things we wanted to compare between MongoDB and RethinkDB is performance. In its current form, our examiner report generates its statistics live, so whatever we use in the backend needs to be quick. We could speed up generation using precomputation (by using a system like CouchDB with views), but since we do a lot of ad-hoc work every day for custom analytics and for the development of future products, we need good performance right away. To test MongoDB and RethinkDB, we wanted to use real-world examples, specifically drawing from Juristat’s products. Two of the longest queries are 1) allowance rates and 2) average number of office actions, both of which were tested in this investigation. To run the tests, we used 50,000 applications (which include all of the data about a given application, the exchange of documents between the USPTO and the attorneys, and the attorneys themselves). We then indexed the data based on key fields, such as examiner names or application numbers, to increase query speeds. Once everything was imported, we went to work rewriting the two queries in the best way possible for each database system.
The Results
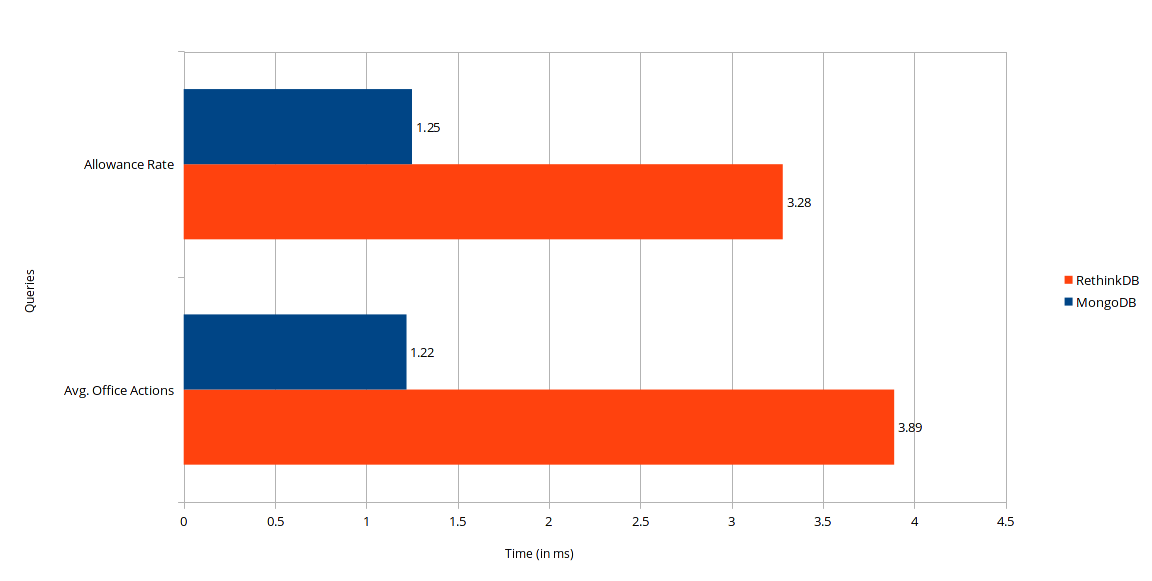
Here are the results after 10,000 repetitions of our queries:
For both queries, MongoDB looks to be about three times faster than RethinkDB. Even before we tested it over the 10,000 trials, we anecdotally noticed that RethinkDB was a bit slower, but the script confirmed it. One benchmark that we did not formally attempt, at least averaged over many trials, was to re-run the queries without filtering for any specific examiner. This effectively nets the USPTO’s own allowance rate and average office actions. On MongoDB, the query took longer, at most 6 seconds per query (as opposed to a fraction of a second). However, RethinkDB scaled up terribly, taking anywhere from 2 to 3 minutes.
An Interesting Quirk
One of the strategies we recommend when constructing MongoDB’s aggregation queries is to strip away as much data as you can at any given stage, once you know you are not going to need it. This can be achieved with the “$project” statement, which can rename or remove fields from documents as they pass through the aggregation. We used this at the very beginning of each of our queries, as both examine only the sequence of document codes for a given application. we found that stripping the unneeded data massively improved the performance of our queries. We then added more statements to our RethinkDB queries to strip data out and see if it would behave the same way as MongoDB. However, RethinkDB did not seem to improve whether we stripped data or not. We are not sure if this means that RethinkDB is already intelligent enough to ignore data it does not need, or if it means that RethinkDB is not optimized enough to show any performance improvements. It is an interesting quirk nevertheless.
Conclusion
From our experience in writing the queries and in benchmarking each database system, it is clear that, for our uses, MongoDB is the best solution. At this point in time, it is simply faster and more optimized than RethinkDB. MongoDB has its downsides, specifically on the sharding front (the complex set of config servers, routers, and more), but it is hard to pick RethinkDB without more maturity, despite its slick UX/UI.
Authored by: Jake Bailey, Intern at Juristat, Computer Science - University of Illinois '17
